Data Collection
Hyperspectral Sensor
We use the LightGene Hyperspectral Sensor for the data collect. Fig.3 is a brief review of the LightGene camera sensor. In particular, the camera can provide hyperspectral dataset in the range of 450~950nm with a spectral resolution at 4nm. In total, the camera can provide 125 spectral channels. The spectral resolution of each channel is approximately 1773 by 1379 pixels. And therefore, in total, each frame of the hyperspectral image is with the size: 1773 * 1379 * 125.
Outdoor data collection in Shanghai
The dataset collection is in Shanghai for three days in June. The we collected data in a variety of environment including: crowded traffic area, famous buildings and structures, CBD, highways, quite suburbs, overpasses and underground parking. The weather condition includes sunny and cloudy days. And the lighting condition includes day, night and sunset. We use standard color board for color calibration. We collecting data, the car is driving at a speed in the range of 20-50km/h. The hyperspectral camera is working at 1fps. The field of view (FOV) is 9 degrees in current lens configuration. The camera is vertical mounted to enable capturing of a wider dynamic range.
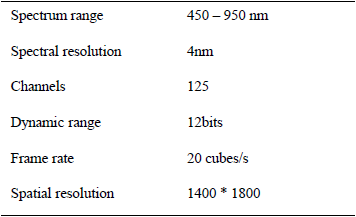
Fig.3. Specifications of the hyperspectral data
Dataset Labeling
Data selection
The V1.0 dataset is focusing on semantic segmentation using coarse labeling. It is aiming to exploit the rich information in the hyperspectral data. Therefore, we manually selected 367 hyperspectral images which are considered suitable for the semantic segmentation task.
Coarse Labeling
For the training dataset, we provide only the coarse labeling. The label is deliberate down in a quick and easy fashion from 10 different people. And the level of detail is various from people to people. Therefore, we are encouraging the users to learn information from the rich hyperspectral information rather than from labeling. Fig.1 shows an example of the coarse labeling. We label 367 images from the dataset and consider them as training set.
We use LabelMe[2] as the labeling tool. And the labels and colors are consistent with CitiScape[1] dataset.
Fine-grained Labeling
For testing purpose, we also fine-grained labeled 68 images. During the challenge, only the input hyperspectral images are available and the groundtruth will not be release.
Hyperspectral Image Compression
Unlike RGB images which only has 3 channels, each hyperspectral images in our dataset has 125 channels. Without compression, each hyperspectral cubic will take more than 1Gigabytes storage and will make it unreasonable for online transfer. In our current release, we compress the image using H.264 encoder and decoder with a quality setting at 90%. The compression ratio is smaller than 2% and the final dataset size is around 40 Gigabytes.